最近有个需求,要修改现有存储结构,涉及查询条件和查询效率的考量,看了几篇索引和HBase相关的文章,回忆了相关知识,结合项目需求,说说自己的理解和总结。
前几篇文章重点介绍MySQL索引相关的知识,从索引优点、索引结构演化过程,到SQL查询过程、执行计划,再到最后的索引优化,错过的朋友可以回顾下前几篇文章:
后面会开始介绍HBase索引相关的,和MySQL对比下,以加深对索引的理解,本篇先介绍下HBase,它的一些特性和整体架构,为后面介绍索引做准备,通过介绍,你会了解到:
- 为什么会出现HBase
- HBase的特性
- HBase的整体架构
部分内容摘录了几个博友的文章,最后会给出文章链接,感谢他们的精彩分析。
为什么会出现HBase
任何一个技术的出现都是有原因的,了解它为什么出现,以及它解决了什么问题,更有助于理解它的特性和设计思想。
MySQL瓶颈
MySQL是一个关系型数据库,有很高的数据一致性和持久性保证,当访问量特别高时,特别是写入操作,会有很大的O性能瓶颈。
虽然可以通过主从读写分离、分库分表的方式解决,但随着数据量不断增大、并发不断增高,MySQL应用开发越来越复杂,也越来越具有技术挑战性。
另外,分表分库的规则的设定都是需要经验的,虽然有Cobar、MyCat、Sharding-JDBC、TDDL、DBProxy中间件层来屏蔽开发者的复杂性,但是避免不了整个架构的复杂性。
分库分表的子库到一定阶段又面临扩展问题,需求的变更可能又需要一种新的sharding。
MySQL的扩展性差、大数据下IO压力大、表结构更改困难,正是MySQL开发人员面临的问题,也是MySQL的瓶颈。
虽然有这些瓶颈,但对数据一致性要求特别高的业务,还是要使用它,但是有的应用场景不需要太高的一致性,在大数据量、高并发的业务中,可以选择其他存储方案。
NOSQL的出现
NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性,数据之间无关系,这样就非常容易扩展。
NOSQL有如下特点:
- 模式自由:不像传统的关系型数据库需要定义数据库、数据表等结构才可以存取数据,数据表中的每一条记录都可能有不同的属性和格式;
- 逆范式:去除约束,降低事务要求,更利于数据的分布式存储,与MySQL范式相反;
- 多分区存储:存储在多个节点上,很好地进行水平扩展,提高数据的读、写性能;
- 多副本异步复制:为了保证数据的安全性,会保存数据的多个副本;
- 弹性可扩展:可以在系统运行过程中动态的增删节点,数据自动平衡移动,不需要人工的干预操作;
- 软事务:事务是关系型数据库的一个特点,NoSQL数据库不能完全满足事务的ACID特性,但是能保证事务的最终一致性;
NOSQL有一些理论支持:
- CAP理论:就是平衡一致性、可用性、分区容错性,因为最多只能同时实现2个,需要做平衡取舍;
- BASE模型:Basically Availble 基本可用,Soft state 状态可以有一段时间不同步,Eventual Consistency 最终一致性,不保证在任意时刻任意节点上的同一份数据都是相同的,但是随着时间的迁移,不同节点上的同一份数据总是在向趋同的方向变化;
放上网上的一张图,可以看到不同数据库测试点不同:
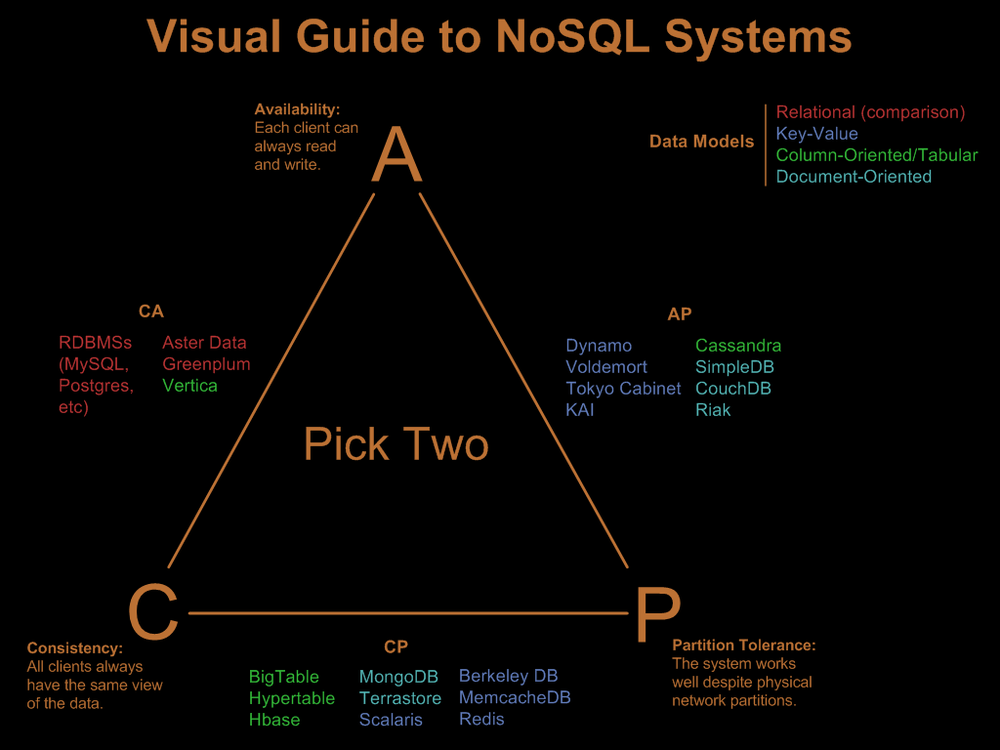
上图也根据颜色区分了不同的数据模型,这里简单总结下。
关系型数据库:一直在介绍的MySQL,就不说了;
键值:内容缓存,主要用于处理大量数据的高访问负载,查找速度快,但数据无结构化,通常只被当作字符串或者二进制数据,比如Redis、MemcacheDB;
列存储数据库:分布式的文件系统,按列存储,针对某一列或者某几列的查询有非常大的IO优势,以列簇式存储,将同一列数据存在一起,查找速度快,可扩展性强,更容易进行分布式扩展,但功能相对局限,比如BigTable、HBase、Cassandra;
文档型数据库:存储类似JSON格式的内容,可对某些字段建立索引功能,是最像关系型的数据库,Key-Value对应的键值对,Value为结构化数据,数据结构要求不严格,表结构可变,但查询性能不高,而且缺乏统一的查询语法,比如MongoDB、CouchDB;
HBase产生背景
上面提到,随着数据规模越来越大,大量业务场景开始考虑数据存储的水平扩展,海量数据量存储成为提升应用性能的瓶颈,单台机器无法负载海量的数据处理,随之而来的出现了很多的分布式存储解决方案,HBase就是其中之一。
HBase--DataBase on Hadoop,基于分布式文件系统上面建立的数据库,HBase是面向列的开源数据库。
开源团队根据2008年Google发布了一篇关于Google搜索引擎BigTable的核心思想的论文,实现了基于分布式文件系统的列数据库。
随后加入Apache基金会,成为Hadoop生态圈中的顶级项目被大家熟知。
HBase的特性
高性能
HBase中存储了一套HDFS的索引,通过表名->行健->列族->列限定符->时间版本这一套索引来定位数据的位置,HBase为每一列数据维护了一套索引规则,对于具体某一具体条数据的查询可以非常快速的通过B+树定位数据存储位置并将其取出。
另外,HBase通常以集群部署,数据被分散到多个节点存储,当客户端发起查询请求的时候,集群里面多个节点并行执行查询操作,最后将不同节点的查询结果进行合并返回给客户端,提高IO性能。
高可用
HBase集群中任意一个节点宕机都不会导致集群瘫痪。这取决于两方面原因:
第一方面,ZooKeeper解决了HBase中心化问题;
另一方面,HBase将数据存放在HDFS上面,HDFS的数据冗余存放在不同节点,一个节点瘫痪可从其他节点取得数据,保证了HBase的高可用。
易扩展
Hbase的扩展性主要体现在两个方面,一个是基于上层处理能RegionServer的扩展,一个是基于存储的扩展HDFS。
无模式
使用HBase不需要预先定义表中有多少列,也不需要定义每一列存储的数据类型,HBase在需要的时候可以动态增加列和指定存储数据类型。
HBase的整体架构
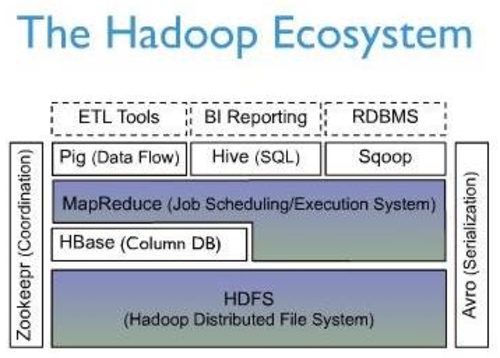
Hbase在整个Hadoop生态圈的地位如下图:
了解几个概念
rowkey:Rowkey的概念和mysql中的主键相似,Hbase使用Rowkey来唯一的区分某一行的数据;
region:和MySQL的分区或者分片差不多,Hbase会将一个大表的数据基于Rowkey的不同范围分配到不通的Region中,每个Region负责一定范围的数据访问和存储;
timestamp:timestamp对Hbase来说至关重要,因为它是实现Hbase多版本的关键,在写入数据的时候,如果用户没有指定对应的timestamp,Hbase会自动添加一个timestamp,timestamp和服务器时间保持一致。相同rowkey的数据按照timestamp倒序排列,默认查询的是最新的版本,可以指定timestamp的值来读取旧版本的数据。
内部基本组成
Hbase的整体主要由zookeeper,Hmaster,HRegionServer,Hdfs文件系统组成,由这四部分共同完成数据的读取与写入。
不同范围的数据被划分到不同地方,称为HRegion,不同的HRegion被放在不同的主机上,当查询数据的时候,只要根据rowkey先找到数据在那个范围的HRegion中,就可以直接到那个HRegion中找到数据,查询效率比传统的数据库快很多。
整体结构
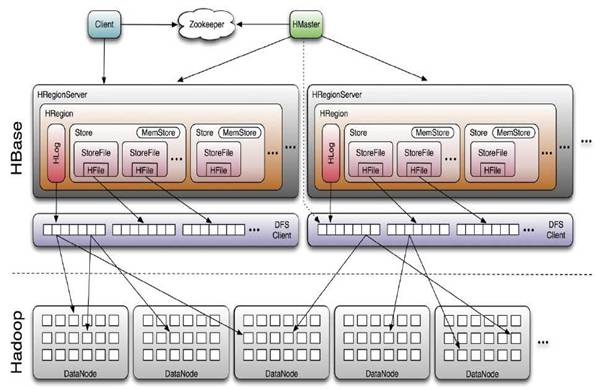
1.HMater
- 在Region Split后,负责新Region的分配;
- 新机器加入时,管理HRegion Server的负载均衡,调整Region分布;
- 在HRegion Server宕机后,负责失效HRegion Server 上的Regions迁移;
2.Region Server
- Region server维护Master分配给它的region,处理对这些region的IO请求;
- HRegion Server管理了很多table的分区,也就是region;
3.Zookeeper
- ZooKeeper为HBase集群提供协调服务,它管理着HMaster和HRegionServer的状态(available/alive等),并且会在它们宕机时通知给HMaster;
- zookeeper中管理着hbase的元数据,例如-root-的位置所在;
4.HDFS
- 数据文件的存放处,由于其本身的分布式存储机制,所以数据文件很安全;
- hadoop的datanode最好和region在同一主机上,方便读取数据,尽量避免网络数据传输;
这篇主要是个引子,下一篇重点介绍下HBase中的索引,以及设计rowkey的一些原则和技巧。
参考文章:
1. 大并发大数量中的MYSQL瓶颈与NOSQL介绍
2. NoSQL你知多少?
3. 大数据Hadoop之HBase认识
4. Hbase技术详细学习笔记
5. Hbase的架构简单解析
本文出自:https://blog.csdn.net/wanshanjay/article/details/80725555

文章评论